I have been contemplating, getting an Ergodox keyboard for a while and I kept putting it off. This holiday season, I put it into my wishlist because, according to my family and friends, I’m notoriously difficult to buy a gift for. I got gifted the Moonlander and it’s been an interesting few days.
First Impressions
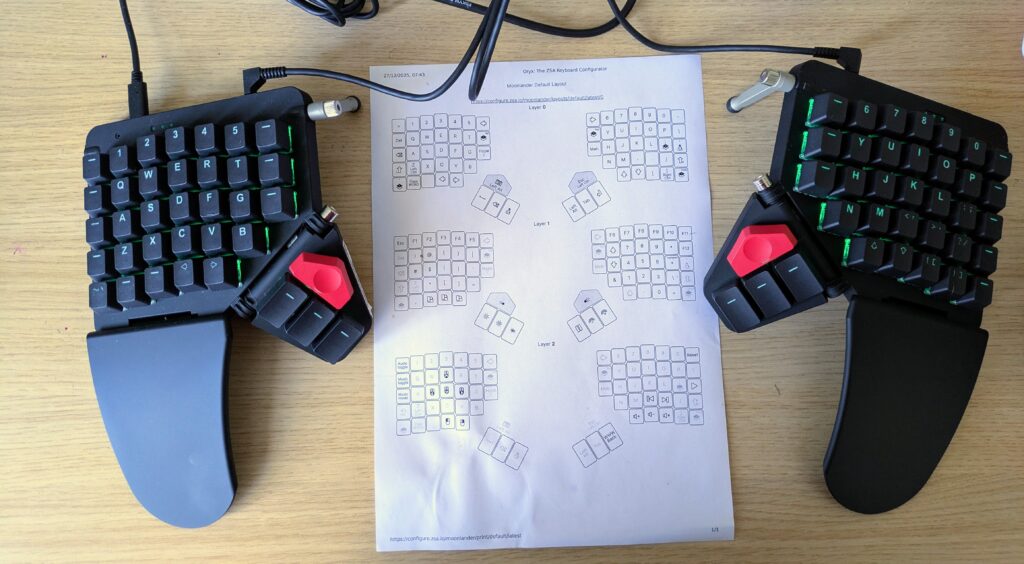
I realised that I never quite touch typed. One of the things, I’m forcing myself to do is to actually learn to touch type. Once I got past that learning curve, it’s not too bad. The Moonlander is quite pretty and compact. I could carry it every day. I’m using the default layout for now. In the first week, my typing speed was around 25 to 30 WPM.
My Moonlander keyboard with a printed layout.
Positives
The second layer having a dedicated numpad is something I enjoy when I’m working with numbers — usually for accounts. Having used a keyboard without a numpad for years, it is super helpful.
Surprises
Backspace where I expect caps lock. I’m still learning to use it.
A single space key. I need to use my left thumb for it.
The position of the Esc key. It’s at my right thumb.
Frustrations
This may be my making by picking the default layout; but some keys always frustrate me. At the moment, combinations that use the Tab key are my stumbling block. I keep having to think really hard to remember how to change windows.
Practice Makes Perfect
Throughout the holidays, I practiced around 6 to 8 times throughout the day. As of today, my typing speed is 70 WPM. I’m even touch typing better than I used to!
A few months ago, we got a puppy! She’s now finishing 3 months with us and she’ll turn 6 months shortly. If nothing else, she forces me to meet my step count goals 🙂
After a few months of training her and her training me, we’ve settled into a reasonably good rhythm.
This year it has officially been 15 years since I started my first job as a web developer. In all these years, I never finished a degree. Since 2021, I’ve been working on a BSc in Information Systems and Information Technology from TU Dublin. The course is modular with several exit paths. One could choose to exit at a Higher Certificate (Level 6/2 years), BSc Ordinary (Level 7/3 years), or BSc Honours (Level 8/4 years). When I started, I was thinking I’d exit at BSc Ordinary but later decided to stick with it for another year just in case I decided to get a Master’s degree in the future.
The view from the Central Quad. I came here for exams every January and May.
The course is fairly modular, you can pick which modules you want to do in every semester at the start of the year. This is unlike most courses at the university and it meant, registration was quite a stressful time every year. While I was never elected the class rep, from the 2nd year onward, I had to step in and talk to the course coordinator regularly at the start of term to get information about the start of classes. We organized ourselves into a Discord server pretty early on and it helped!
The stairs in the Central Quad building. They were always fascinating.
The first 2 years of the course taught us fundamentals. This is probably when I learned the most. The fundamental math and algorithm classes were fun and taught by excellent lecturers. I also got a chance to learn about the theory behind relational databases, networking, and encryption further than I had explored myself. All of these subjects had some great lecturers who went in-depth. In theory, the university would have let me skip some courses, but I explicitly chose not to. I wanted to get a feel for doing the work and allocating time in low stakes courses in the first year. Every semester went something like this: One course were I’m learning new things, 2 courses were what’s being taught is familiar enough and I can probably trivially pick up the new pieces.
Our class started with roughly 18 students. Due to different folks and their availability, not everyone went at the full pace of talking all the subjects in every semester. At the end of the third year, there were 3 of us who were from the start, we adopted 2 more folks who had started before us, but were targeting to finish with us.
The classes were from 6:30 pm to 9:30 pm on Tuesdays to Fridays in most years. The last year of the course was chaotic since the days of the week shuffled around. Additionally, we had to do a project and that had its own classes to talk about the report. I also had a meeting with my project supervisor to top off the class about it. If I had a time machine and choice, I’d probably not try doing the project and a full course load. That nearly burned me out at the end of the academic year.
I approached by assignments like an SRE, it was all version controlled in Git and I wrote most of it with LaTeX. The only exception was a math course that took only 15 mins on paper. It would have taken a good hour with LaTeX. I ended up with a standard LaTeX template for my assignments that I kept reusing. The good news is that it looked consistently good across the board!
Standing in line to get my parchment. Disbelief that this is finally over!
At end of October, we graduated finally! The sense of relief among the 6 of us were palpable! Would I got back for a Master’s degree? Not any time soon. I need the distress and burn out of the last 4 years to leave me before I try that again.
The last time I ran a road marathon was 2016. It’s been nearly 10 years since I did one of those. I tried to run the Cork marathon last year, but the timing was terrible. It was right after the end of semester exams for my BSc course and I couldn’t go out to run for a solid 3 weeks before the race. There’s usually a mad rush of assignments, exam prep, actual exam, and recovering from the mental stress.
This year, I set my sights on Longford Marathon as the big event. The last few years, it’s been Ecotrail Wicklow that’s been my big event of the year. This year, the training block was starting just as my exams were finishing, so it was better than my planning for last year. I missed a few training runs here and there but overall, this was the best training block I’ve had heading into a marathon in a long time.
I drove into Longford the previous afternoon. I had a room booked starting Saturday until Tuesday morning. I didn’t want to drive back immediately after the race. I figured, I’d need an extra day to be rested and ready. This was a good decision in the end. The Longford Arms Hotel was one of the event sponsors and the start/finish line was right outside the hotel. This was an excellent decision. The hotel even had breakfast starting at 6 am the day of the race for the runners to have their breakfast well in advance of the race. I found this extremely kind and welcoming of the folks driving into Longford for the race.
Race gear
The morning of the race, I was all set. I was going to take the Precision gels in a little gel flask. I had enough in the flask for about 2.5h in and I took a few extra large packs of it just in case. One of my bottles had water with electrolytes and one was plain water. I had sun glasses on and a hat. The previous day was a very wet drive but the day of the race was dry. Due to past experiences, I prefer to carry a hydration bag with my gels and some water during races. I have had races where they either run of water or I run out of water when I really want water. This turned out to be an excellent idea for the kind of weather it ended up being.
My goal for the event was 5h, it felt like a not too difficult a goal but I knew how much I struggled at Ecotrail last year after the 30K mark. I was cautiously optimistic going into the race. I was nervous all through the morning. I woke up early and went to get breakfast. The place was packed. I managed to eat some toast and drink some tea. The official start time for the race was 9 am. I was down there at 8:30 am and the energy was intense! The half marathon and the marathoners went out together. All my previous marathons, I always went out a little too fast. This is manageable with a half marathon but I really needed to control it for a full marathon. I kept my pace just around 7 min/km. The course took us out into Longford town and around back to the start line. Then it turned off.
The start line of the race.
Once we turned off from the town, people started to thin out as the initial surge of energy wore off and people started slowing down. Very quickly, the marathoners and the half marathoners were split off across 2 sides of the road. The half marathoners turned off at the roundabout ahead while the marathoners pushed on ahead. I stuck to a group of people from around the 5th km and they were around me for most of the race.
At some point, I started chatting with a fellow runner who was going a tad bit faster than me. We were talking and it was easy enough to keep pace with her. Turns out, she was running the Ultra marathon! And she was faster than me trying to run a marathon. I had to slow down after a km or so since I was worried I’d end up crashing and burning.
The best part about this race is the views. I takes you through some gorgeous Irish countryside with sheep and cows grazing along the pastures. At the 11K mark, I saw a few folks who were clearly there to cheer on their friends. They had some great posters. The funniest one was one that said “Speed Van Ahead”. They kept moving along to keep up with their friend, so I saw them at least 3 times along the route and at the finish line. Every time I saw them, I had to smile. They put a spring to my step on the last few km when I saw them.
The gorgeous views
Unusually, I started feeling tired around the 20 km. Even at the slow pace. This was super unusual since I’m usually able to keep at it for about 25 km during training without too much trouble (except for that one time, which we shall not speak about). The aid stations were well stocked with water, though, as someone carrying their own water, I was at a disadvantage. I had to stop, take my bottles off, and refill it. It didn’t help that one of my flasks started having a bad seal during the race, so it would fill up with air as I drank water and slosh around. That got annoying really quickly.
I had to take walk breaks from then on. I tried to 30 sec run/walks for the rest of the race until there was a hill. The race had a bunch of small hills but stretched out over a long distance. That was rather annoying because those bits of the route also had no shade. I was grateful I had a hat. I was strong enough to keep my position but I didn’t feel strong enough to overtake.
It was really tempting to walk at the 32K mark, but I kept remembering Sarah telling me that the goal is to keep moving. At this point, I knew I was not going to hit the pace I planned. I was a little disappointed, but I was trying to look at the positives. I felt tired, but I was not in extreme pain. Usually, at this point, my core hurts to move. None of that this time. It was just a matter of gathering enough energy to put one foot in front of the other and keep moving. There were folks overtaking me, all of them were ultra marathoners. And they all cheered me on as I was moving. And I cheered them right back.
Even the cars on the road would honk, lower their windows, and clap as they passed. At some of the sections of the national road, where it was dangerous for runners to be on the side, they closed off an entire lane so that we had enough buffer to run and overtake each other safely.
Zoom in for the “Speed Van Ahead” sign
The last 3 km of the race were the most brutal. There was a huge climb up over a railway bridge and then back down to the ground under either a national road or a motorway. I was too tired to look up which one. I was walking along with yet another ultramarathoner and we were both having a little whine about the long uphill back up to the main road. I knew I had it in me to do a nice fast km or maybe 1.5 km. I figure once the hill was over, I’d start running and see how it felt.
This is when I noticed that I most definitely had blisters on my toes. It felt at the time like the blister had burst. I thought about checking but I realized, there was no point. There was nothing I could do and I’d have to wait until after the race to get it checked. That’s where I’d find paramedics nearby. I started a gentle trot at the end of the hill, testing the feeling in my legs. Every step hurt my toes a little bit, but once I got moving, it felt easy to keep going.
The last km ended up being the fastest of the entire race. I was surprised I had so much strength left in me. I picked up the medal and walked straight into my room. I didn’t feel like food or water. In fact, I felt like throwing up. But first, I had to confront one of the only downsides to the hotel — I had to walk up a flight of stairs to my room.
Despite not meting my goal pace, I still ran my fastest marathon so far at 5h39m. This was fun. I was texting my coach once I felt better about what I wanted to do for 2026. I’m setting myself up for some loftier goals — A half marathon faster than 2h and a full marathon faster than 4h30m.
In 2023, I had a modest goal of 26 books, and I managed 19. In 2024, I had a more ambitious goal of 52 books and finished 53 books. Most of my reading was a combination of e-books and audiobooks from my local library. While this isn’t all the authors, these are some of the authors I found notable and a great read.
Richard Osman
I’ve read both the Thursday Murder Club series and the new book We Solve Murders. I enjoy his pace and writing style.
Atlee Pine series from David Baldacci
I haven’t read the first book in the series yet since it’s always had a long wait on the library app. But the remaining ones that I’ve read or listened to are ones I liked. They’re fast paced and hard to put down. I remember staying up until 5 am finishing up the last book!
Carmel Harrington
In my question to listen to more Irish authors, I listened to The Girl from Donegal. The story was captivating and the voice actors were good at the different accents. I wasn’t sure I would enjoy historical fiction, but it was lovely! I went on to read a few more books by the same author. My current favorite is The Moon Over Kilmore Quay. I describe her books as time travel books. There is usually a combination of past and present over time that meet.
Fiona McArthur
I stumbled on Midwife on the Orient Express, most likely because it was a book available without wait. I proceeded to listen to all the books I could find by the author. It was fascinating to read about the remote corners of Australia.
The topic of healthcare and life in remote Australia was fascinating! I went onto read Beth Mcrae’s Outback Midwife detailing her career over 40 years.
Matthew Reilly
I’ve read and owned several of Matthew Reilly’s books in the past. I’m pretty sure I’ve owned Seven Ancient Wonders but I read it so long ago that I had to re-read. I’ve been working my way through that series. It was an excellent read. I tend to think of it as an Indiana Jones style book series.
Patricia Cornwell
The first book I picked up was when in 2004, about 20 years ago. I’ve actually never read the first few books or read the books in an organized manner. This year, I made an effort to read/listen to some of the books in order. It’s somewhat fascinating to hear a book set in the 90s. It took a bit for me to adjust to everyone smoking in their cars, offices, and so on.
How to Train Your Dragon by Cressida Cowell
Yes, you’ve probably heard of the movie. But the audiobook is narrated by David Tenant and he gives a different voice to every character! There are 12 books and I’ve finished all but 2 in the middle. The wait time for those books run up to July 2025! I have them reserved. It is an excellent coming of age series. It is a children’s book, just like Harry Potter is a children’s book. I’d say it’s suitable for all ages!
There were many more excellent books from the last year, but these are the authors I enjoyed reading.